CEDMAV Publications
2013


D. Maljovec, Bei Wang, D. Mandelli, P.-T. Bremer, V. Pascucci.
“Analyze Dynamic Probabilistic Risk Assessment Data through Clustering,” In Proceedings of the 2013 International Topical Meeting on Probabilistic Safety Assessment and Analysis (PSA 2013), 2013.
ABSTRACT
We investigate the use of a topology-based clustering technique on the data generated by dynamic event tree methodologies. The clustering technique we utilizes focuses on a domain-partitioning algorithm based on topological structures known as the Morse-Smale complex, which partitions the data points into clusters based on their uniform gradient flow behavior. We perform both end state analysis and transient analysis to classify the set of nuclear scenarios. We demonstrate our methodology on a dataset generated for a sodium-cooled fast reactor during an aircraft crash scenario. The simulation tracks the temperature of the reactor as well as the time for a recovery team to fix the passive cooling system. Combined with clustering results obtained previously through mean shift methodology, we present the user with complementary views of the data that help illuminate key features that may be otherwise hidden using a single methodology. By clustering the data, the number of relevant test cases to be selected for further analysis can be drastically reduced by selecting a representative from each cluster. Identifying the similarities of simulations within a cluster can also aid in the drawing of important conclusions with respect to safety analysis.
D. Maljovec, Bei Wang, A. Kupresanin, G. Johannesson, V. Pascucci, P.-T. Bremer.
“Adaptive Sampling with Topological Scores,” In Int. J. Uncertainty Quantification, Vol. 3, No. 2, Begell House, pp. 119--141. 2013.
DOI: 10.1615/int.j.uncertaintyquantification.2012003955
ABSTRACT
Understanding and describing expensive black box functions such as physical simulations is a common problem in many application areas. One example is the recent interest in uncertainty quantification with the goal of discovering the relationship between a potentially large number of input parameters and the output of a simulation. Typically, the simulation of interest is expensive to evaluate and thus the sampling of the parameter space is necessarily small. As a result choosing a "good" set of samples at which to evaluate is crucial to glean as much information as possible from the fewest samples. While space-filling sampling designs such as Latin hypercubes provide a good initial cover of the entire domain, more detailed studies typically rely on adaptive sampling: Given an initial set of samples, these techniques construct a surrogate model and use it to evaluate a scoring function which aims to predict the expected gain from evaluating a potential new sample. There exist a large number of different surrogate models as well as different scoring functions each with their own advantages and disadvantages. In this paper we present an extensive comparative study of adaptive sampling using four popular regression models combined with six traditional scoring functions compared against a space-filling design. Furthermore, for a single high-dimensional output function, we introduce a new class of scoring functions based on global topological rather than local geometric information. The new scoring functions are competitive in terms of the root mean squared prediction error but are expected to better recover the global topological structure. Our experiments suggest that the most common point of failure of adaptive sampling schemes are ill-suited regression models. Nevertheless, even given well-fitted surrogate models many scoring functions fail to outperform a space-filling design.
V. Pascucci, P.-T. Bremer, A. Gyulassy, G. Scorzelli, C. Christensen, B. Summa, S. Kumar.
“Scalable Visualization and Interactive Analysis Using Massive Data Streams,” In Cloud Computing and Big Data, Advances in Parallel Computing, Vol. 23, IOS Press, pp. 212--230. 2013.
ABSTRACT
Historically, data creation and storage has always outpaced the infrastructure for its movement and utilization. This trend is increasing now more than ever, with the ever growing size of scientific simulations, increased resolution of sensors, and large mosaic images. Effective exploration of massive scientific models demands the combination of data management, analysis, and visualization techniques, working together in an interactive setting. The ViSUS application framework has been designed as an environment that allows the interactive exploration and analysis of massive scientific models in a cache-oblivious, hardware-agnostic manner, enabling processing and visualization of possibly geographically distributed data using many kinds of devices and platforms.
For general purpose feature segmentation and exploration we discuss a new paradigm based on topological analysis. This approach enables the extraction of summaries of features present in the data through abstract models that are orders of magnitude smaller than the raw data, providing enough information to support general queries and perform a wide range of analyses without access to the original data.
Keywords: Visualization, data analysis, topological data analysis, Parallel I/O
S. Philip, B. Summa, J. Tierny, P.-T. Bremer, V. Pascucci.
“Scalable Seams for Gigapixel Panoramas,” In Proceedings of the 2013 Eurographics Symposium on Parallel Graphics and Visualization, Note: Awarded Best Paper!, pp. 25--32. 2013.
DOI: 10.2312/EGPGV/EGPGV13/025-032
ABSTRACT

Gigapixel panoramas are an increasingly popular digital image application. They are often created as a mosaic of smaller images composited into a larger single image. The mosaic acquisition can occur over many hours causing the individual images to differ in exposure and lighting conditions. Therefore, to give the appearance of a single seamless image a blending operation is necessary. The quality of this blending depends on the magnitude of discontinuity along the boundaries between the images. Often image boundaries, or seams, are first computed to minimize this transition. Current techniques based on the multi-labeling Graph Cuts method are too slow and memory intensive for panoramas many gigapixels in size. In this paper we present a multithreaded out-of-core seam computing technique that is fast, has a small memory footprint, and gives near perfect scaling up to the number of physical cores of our test system. With this method the time required to compute image boundaries for gigapixel imagery improves from many hours (or even days) to just a few minutes on commodity hardware while still producing boundaries with energy that is on-par, if not better, than Graph Cuts.
A. Rungta, B. Summa, D. Demir, P.-T. Bremer, V. Pascucci.
“ManyVis: Multiple Applications in an Integrated Visualization Environment,” In IEEE Transactions on Visualization and Computer Graphics (TVCG), Vol. 19, No. 12, pp. 2878--2885. December, 2013.
ABSTRACT
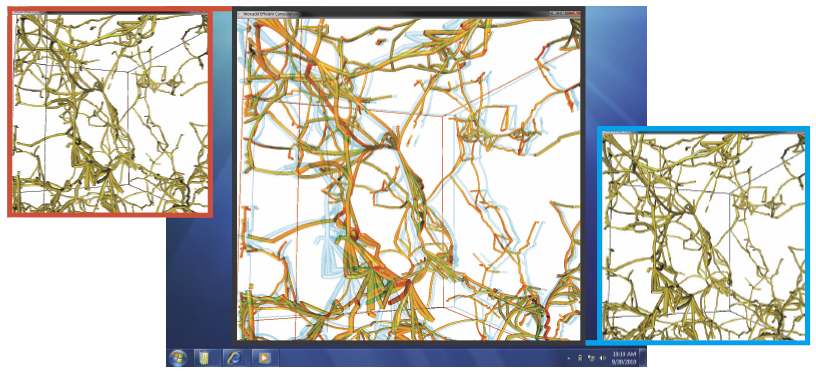
As the visualization field matures, an increasing number of general toolkits are developed to cover a broad range of applications. However, no general tool can incorporate the latest capabilities for all possible applications, nor can the user interfaces and workflows be easily adjusted to accommodate all user communities. As a result, users will often chose either substandard solutions presented in familiar, customized tools or assemble a patchwork of individual applications glued through ad-hoc scripts and extensive, manual intervention. Instead, we need the ability to easily and rapidly assemble the best-in-task tools into custom interfaces and workflows to optimally serve any given application community. Unfortunately, creating such meta-applications at the API or SDK level is difficult, time consuming, and often infeasible due to the sheer variety of data models, design philosophies, limits in functionality, and the use of closed commercial systems. In this paper, we present the ManyVis framework which enables custom solutions to be built both rapidly and simply by allowing coordination and communication across existing unrelated applications. ManyVis allows users to combine software tools with complementary characteristics into one virtual application driven by a single, custom-designed interface.
P. Skraba, Bei Wang, G. Chen, P. Rosen.
“2D Vector Field Simplification Based on Robustness,” SCI Technical Report, No. UUSCI-2013-004, SCI Institute, University of Utah, 2013.
ABSTRACT
Vector field simplification aims to reduce the complexity of the flow by removing features in order of their relevance and importance, to reveal prominent behavior and obtain a compact representation for interpretation. Most existing simplification techniques based on the topological skeleton successively remove pairs of critical points connected by separatrices using distance or area-based relevance measures. These methods rely on the stable extraction of the topological skeleton, which can be difficult due to instability in numerical integration, especially when processing highly rotational flows. Further, the distance and area-based metrics are used to determine the cancellation ordering of features from a geometric point of view. Specifically, these metrics do not consider the flow magnitude, which is an important physical property of the flow. In this paper, we propose a novel simplification scheme derived from the recently introduced topological notion of robustness, which provides a complementary flow structure hierarchy to the traditional topological skeleton-based approach. Robustness enables the pruning of sets of critical points according to a quantitative measure of their stability, that is, the minimum amount of vector field perturbation required to remove them within a local neighborhood. This leads to a natural hierarchical simplification scheme with more physical consideration than purely topological-skeleton-based methods. Such a simplification does not depend on the topological skeleton of the vector field and therefore can handle more general situations (e.g. centers and pairs not connected by separatrices). We also provide a novel simplification algorithm based on degree theory with fewer restrictions and so can handle more general boundary conditions. We provide an implementation under the piecewise-linear setting and apply it to both synthetic and real-world datasets.
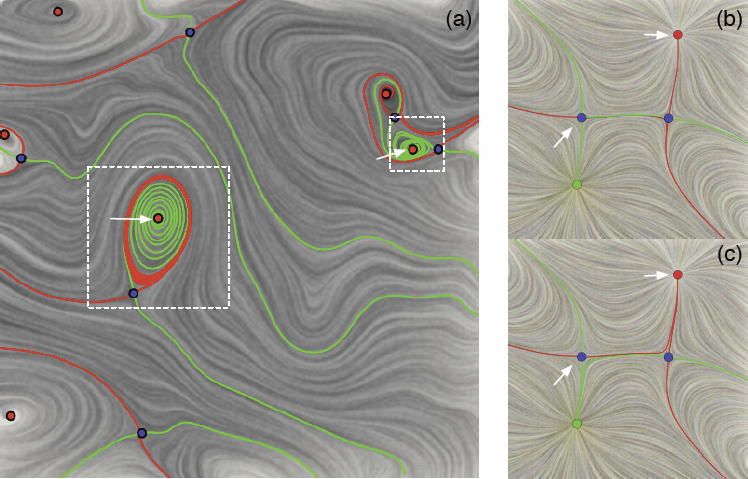
Bei Wang, P. Rosen, P. Skraba, H. Bhatia, V. Pascucci.
“Visualizing Robustness of Critical Points for 2D Time-Varying Vector Fields,” In Computer Graphics Forum, Vol. 32, No. 3, Wiley-Blackwell, pp. 221--230. jun, 2013.
DOI: 10.1111/cgf.12109
ABSTRACT
Analyzing critical points and their temporal evolutions plays a crucial role in understanding the behavior of vector fields. A key challenge is to quantify the stability of critical points: more stable points may represent more important phenomena or vice versa. The topological notion of robustness is a tool which allows us to quantify rigorously the stability of each critical point. Intuitively, the robustness of a critical point is the minimum amount of perturbation necessary to cancel it within a local neighborhood, measured under an appropriate metric. In this paper, we introduce a new analysis and visualization framework which enables interactive exploration of robustness of critical points for both stationary and time-varying 2D vector fields. This framework allows the end-users, for the first time, to investigate how the stability of a critical point evolves over time. We show that this depends heavily on the global properties of the vector field and that structural changes can correspond to interesting behavior. We demonstrate the practicality of our theories and techniques on several datasets involving combustion and oceanic eddy simulations and obtain some key insights regarding their stable and unstable features.
Bo Wang, M. Prastawa, A. Saha, S.P. Awate, A. Irimia, M.C. Chambers, P.M. Vespa, J.D. Van Horn, V. Pascucci, G. Gerig.
“Modeling 4D changes in pathological anatomy using domain adaptation: analysis of TBI imaging using a tumor database,” In Proceedings of the 2013 MICCAI-MBIA Workshop, Lecture Notes in Computer Science (LNCS), Vol. 8159, Note: Awarded Best Paper!, pp. 31--39. 2013.
DOI: 10.1007/978-3-319-02126-3_4
ABSTRACT
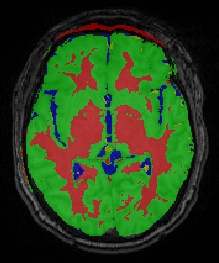
Analysis of 4D medical images presenting pathology (i.e., lesions) is signi cantly challenging due to the presence of complex changes over time. Image analysis methods for 4D images with lesions need to account for changes in brain structures due to deformation, as well as the formation and deletion of new structures (e.g., edema, bleeding) due to the physiological processes associated with damage, intervention, and recovery. We propose a novel framework that models 4D changes in pathological anatomy across time, and provides explicit mapping from a healthy template to subjects with pathology. Moreover, our framework uses transfer learning to leverage rich information from a known source domain, where we have a collection of completely segmented images, to yield effective appearance models for the input target domain. The automatic 4D segmentation method uses a novel domain adaptation technique for generative kernel density models to transfer information between different domains, resulting in a fully automatic method that requires no user interaction. We demonstrate the effectiveness of our novel approach with the analysis of 4D images of traumatic brain injury (TBI), using a synthetic tumor database as the source domain.
G.H. Weber, K. Beketayev, P.-T. Bremer, B. Hamann, M. Haranczyk, M. Hlawitschka, V. Pascucci.
“Comprehensible Presentation of Topological Information,” No. LBNL-5693E, Lawrence Berkeley National Laboratory, 2013.
ABSTRACT
Topological information has proven very valuable in the analysis of scientific data. An important challenge that remains is presenting this highly abstract information in a way that it is comprehensible even if one does not have an in-depth background in topology. Furthermore, it is often desirable to combine the structural insight gained by topological analysis with complementary information, such as geometric information. We present an overview over methods that use metaphors to make topological information more accessible to non-expert users, and we demonstrate their applicability to a range of scientific data sets. With the increasingly complex output of exascale simulations, the importance of having effective means of providing a comprehensible, abstract overview over data will grow. The techniques that we present will serve as an important foundation for this purpose.
W. Widanagamaachchi, P. Rosen, V. Pascucci.
“A Flexible Framework for Fusing Image Collections into Panoramas,” In Proceedings of the 2013 SIBGRAPI Conference on Graphics, Patterns, and Images, Note: Awarded Best Paper., pp. 195-202. 2013.
DOI: 10.1109/SIBGRAPI.2013.35
ABSTRACT

Panoramas create summary views of multiple images, which make them a valuable means of analyzing huge quantities of image and video data. This paper introduces the Ray Graph - a general framework for panorama construction. With rays as its vertices, the Ray Graph uses its edges to specify a set of coherency relationships among all input rays. Consequently, by using a set of simple graph traversal rules, a diverse set of panorama structures can be enumerated, which can be used to efficiently and robustly generate panoramic images from image collections. To demonstrate this framework, we first use it to recreate both 360° and street panoramas. We further introduce two new panorama models, the centipede panorama - a hybrid of the 360° and street panoramas, and the storytelling panorama - a time encoding panorama. Finally, we demonstrate the flexibility of this framework by enabling interactive brushing of panoramic regions for removal of undesired features such as occlusions and moving objects.
2012
J.C. Bennett, H. Abbasi, P. Bremer, R.W. Grout, A. Gyulassy, T. Jin, S. Klasky, H. Kolla, M. Parashar, V. Pascucci, P. Pbay, D. Thompson, H. Yu, F. Zhang, J. Chen.
“Combining In-Situ and In-Transit Processing to Enable Extreme-Scale Scientific Analysis,” In ACM/IEEE International Conference for High Performance Computing, Networking, Storage, and Analysis (SC), Salt Lake City, Utah, U.S.A., November, 2012.
ABSTRACT

With the onset of extreme-scale computing, I/O constraints make it increasingly difficult for scientists to save a sufficient amount of raw simulation data to persistent storage. One potential solution is to change the data analysis pipeline from a post-process centric to a concurrent approach based on either in-situ or in-transit processing. In this context computations are considered in-situ if they utilize the primary compute resources, while in-transit processing refers to offloading computations to a set of secondary resources using asynchronous data transfers. In this paper we explore the design and implementation of three common analysis techniques typically performed on large-scale scientific simulations: topological analysis, descriptive statistics, and visualization. We summarize algorithmic developments, describe a resource scheduling system to coordinate the execution of various analysis workflows, and discuss our implementation using the DataSpaces and ADIOS frameworks that support efficient data movement between in-situ and in-transit computations. We demonstrate the efficiency of our lightweight, flexible framework by deploying it on the Jaguar XK6 to analyze data generated by S3D, a massively parallel turbulent combustion code. Our framework allows scientists dealing with the data deluge at extreme scale to perform analyses at increased temporal resolutions, mitigate I/O costs, and significantly improve the time to insight.
A. Bhatele, T. Gamblin, S.H. Langer, P.-T. Bremer, E.W. Draeger, B. Hamann, K.E. Isaacs, A.G. Landge, J.A. Levine, V. Pascucci, M. Schulz, C.H. Still.
“Mapping applications with collectives over sub-communicators on torus networks,” In Proceedings of Supercomputing 2012, pp. 1--11. 2012.
DOI: 10.1109/SC.2012.75
ABSTRACT
The placement of tasks in a parallel application on specific nodes of a supercomputer can significantly impact performance. Traditionally, this task mapping has focused on reducing the distance between communicating tasks on the physical network. This minimizes the number of hops that point-to-point messages travel and thus reduces link sharing between messages and contention. However, for applications that use collectives over sub-communicators, this heuristic may not be optimal. Many collectives can benefit from an increase in bandwidth even at the cost of an increase in hop count, especially when sending large messages. For example, placing communicating tasks in a cube configuration rather than a plane or a line on a torus network increases the number of possible paths messages might take. This increases the available bandwidth which can lead to significant performance gains.
We have developed Rubik, a tool that provides a simple and intuitive interface to create a wide variety of mappings for structured communication patterns. Rubik supports a number of elementary operations such as splits, tilts, or shifts, that can be combined into a large number of unique patterns. Each operation can be applied to disjoint groups of processes involved in collectives to increase the effective bandwidth. We demonstrate the use of Rubik for improving performance of two parallel codes, pF3D and Qbox, which use collectives over sub-communicators.
F. Chen, H. Obermaier, H. Hagen, B. Hamann, J. Tierny, V. Pascucci..
“Topology Analysis of Time-Dependent Multi-Fluid Data Using the Reeb Graph,” In Computer Aided Geometric Design, Note: Published online Apr 24., Elsevier, 2012.
DOI: 10.1016/j.cagd.2012.03.019
ABSTRACT

Liquid–liquid extraction is a typical multi-fluid problem in chemical engineering where two types of immiscible fluids are mixed together. Mixing of two-phase fluids results in a time-varying fluid density distribution, quantitatively indicating the presence of liquid phases. For engineers who design extraction devices, it is crucial to understand the density distribution of each fluid, particularly flow regions that have a high concentration of the dispersed phase. The propagation of regions of high density can be studied by examining the topology of isosurfaces of the density data. We present a topology-based approach to track the splitting and merging events of these regions using the Reeb graphs. Time is used as the third dimension in addition to two-dimensional (2D) point-based simulation data. Due to low time resolution of the input data set, a physics-based interpolation scheme is required in order to improve the accuracy of the proposed topology tracking method. The model used for interpolation produces a smooth time-dependent density field by applying Lagrangian-based advection to the given simulated point cloud data, conforming to the physical laws of flow evolution. Using the Reeb graph, the spatial and temporal locations of bifurcation and merging events can be readily identified supporting in-depth analysis of the extraction process.
A.N.M. Imroz Choudhury, Bei Wang, P. Rosen, V. Pascucci.
“Topological Analysis and Visualization of Cyclical Behavior in Memory Reference Traces,” In Proceedings of the IEEE Pacific Visualization Symposium (PacificVis 2012), pp. 9--16. 2012.
DOI: 10.1109/PacificVis.2012.6183557
ABSTRACT
We demonstrate the application of topological analysis techniques to the rather unexpected domain of software visualization. We collect a memory reference trace from a running program, recasting the linear flow of trace records as a high-dimensional point cloud in a metric space. We use topological persistence to automatically detect significant circular structures in the point cloud, which represent recurrent or cyclical runtime program behaviors. We visualize such recurrences using radial plots to display their time evolution, offering multi-scale visual insights, and detecting potential candidates for memory performance optimization. We then present several case studies to demonstrate some key insights obtained using our techniques.
Keywords: scidac
A. Gyulassy, V. Pascucci, T. Peterka, R. Ross.
“The Parallel Computation of Morse-Smale Complexes,” In Proceedings of the Parallel and Distributed Processing Symposium (IPDPS), pp. 484--495. 2012.
DOI: 10.1109/IPDPS.2012.52
ABSTRACT
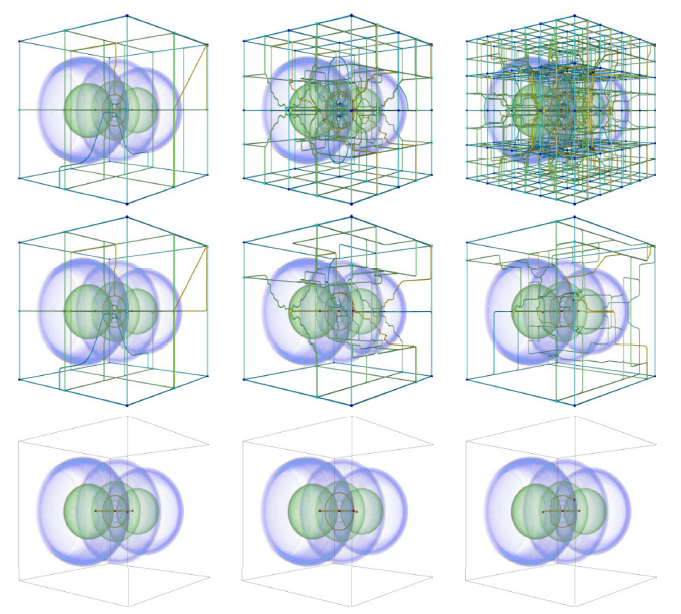
Topology-based techniques are useful for multiscale exploration of the feature space of scalar-valued functions, such as those derived from the output of large-scale simulations. The Morse-Smale (MS) complex, in particular, allows robust identification of gradient-based features, and therefore is suitable for analysis tasks in a wide range of application domains. In this paper, we develop a two-stage algorithm to construct the 1-skeleton of the Morse-Smale complex in parallel, the first stage independently computing local features per block and the second stage merging to resolve global features. Our implementation is based on MPI and a distributed-memory architecture. Through a set of scalability studies on the IBM Blue Gene/P supercomputer, we characterize the performance of the algorithm as block sizes, process counts, merging strategy, and levels of topological simplification are varied, for datasets that vary in feature composition and size. We conclude with a strong scaling study using scientific datasets computed by combustion and hydrodynamics simulations.
A. Gyulassy, P.-T. Bremer, V. Pascucci.
“Computing Morse-Smale Complexes with Accurate Geometry,” In IEEE Transactions on Visualization and Computer Graphics, Vol. 18, No. 12, pp. 2014--2022. 2012.
DOI: 10.1109/TVCG.2011.272
ABSTRACT
Topological techniques have proven highly successful in analyzing and visualizing scientific data. As a result, significant efforts have been made to compute structures like the Morse-Smale complex as robustly and efficiently as possible. However, the resulting algorithms, while topologically consistent, often produce incorrect connectivity as well as poor geometry. These problems may compromise or even invalidate any subsequent analysis. Moreover, such techniques may fail to improve even when the resolution of the domain mesh is increased, thus producing potentially incorrect results even for highly resolved functions. To address these problems we introduce two new algorithms: (i) a randomized algorithm to compute the discrete gradient of a scalar field that converges under refinement; and (ii) a deterministic variant which directly computes accurate geometry and thus correct connectivity of the MS complex. The first algorithm converges in the sense that on average it produces the correct result and its standard deviation approaches zero with increasing mesh resolution. The second algorithm uses two ordered traversals of the function to integrate the probabilities of the first to extract correct (near optimal) geometry and connectivity. We present an extensive empirical study using both synthetic and real-world data and demonstrates the advantages of our algorithms in comparison with several popular approaches.
A. Gyulassy, N. Kotava, M. Kim, C. Hansen, H. Hagen, and V. Pascucci.
“Direct Feature Visualization Using Morse-Smale Complexes,” In IEEE Transactions on Visualization and Computer Graphics, Vol. 18, No. 9, pp. 1549--1562. September, 2012.
DOI: 10.1109/TVCG.2011.272
ABSTRACT
In this paper, we characterize the range of features that can be extracted from an Morse-Smale complex and describe a unified query language to extract them. We provide a visual dictionary to guide users when defining features in terms of these queries. We demonstrate our topology-rich visualization pipeline in a tool that interactively queries the MS complex to extract features at multiple resolutions, assigns rendering attributes, and combines traditional volume visualization with the extracted features. The flexibility and power of this approach is illustrated with examples showing novel features.
S. Kumar, V. Vishwanath, P. Carns, J.A. Levine, R. Latham, G. Scorzelli, H. Kolla, R. Grout, R. Ross, M.E. Papka, J. Chen, V. Pascucci.
“Efficient data restructuring and aggregation for I/O acceleration in PIDX,” In Proceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis, IEEE Computer Society Press, pp. 50:1--50:11. 2012.
ISBN: 978-1-4673-0804-5
ABSTRACT
Hierarchical, multiresolution data representations enable interactive analysis and visualization of large-scale simulations. One promising application of these techniques is to store high performance computing simulation output in a hierarchical Z (HZ) ordering that translates data from a Cartesian coordinate scheme to a one-dimensional array ordered by locality at different resolution levels. However, when the dimensions of the simulation data are not an even power of 2, parallel HZ ordering produces sparse memory and network access patterns that inhibit I/O performance. This work presents a new technique for parallel HZ ordering of simulation datasets that restructures simulation data into large (power of 2) blocks to facilitate efficient I/O aggregation. We perform both weak and strong scaling experiments using the S3D combustion application on both Cray-XE6 (65,536 cores) and IBM Blue Gene/P (131,072 cores) platforms. We demonstrate that data can be written in hierarchical, multiresolution format with performance competitive to that of native data-ordering methods.
A.G. Landge, J.A. Levine, A. Bhatele, K.E. Isaacs, T. Gamblin, S. Langer, M. Schulz, P.-T. Bremer, V. Pascucci.
“Visualizing Network Traffic to Understand the Performance of Massively Parallel Simulations,” In IEEE Transactions on Visualization and Computer Graphics, Vol. 18, No. 12, IEEE, pp. 2467--2476. Dec, 2012.
DOI: 10.1109/TVCG.2012.286
ABSTRACT
The performance of massively parallel applications is often heavily impacted by the cost of communication among compute nodes. However, determining how to best use the network is a formidable task, made challenging by the ever increasing size and complexity of modern supercomputers. This paper applies visualization techniques to aid parallel application developers in understanding the network activity by enabling a detailed exploration of the flow of packets through the hardware interconnect. In order to visualize this large and complex data, we employ two linked views of the hardware network. The first is a 2D view, that represents the network structure as one of several simplified planar projections. This view is designed to allow a user to easily identify trends and patterns in the network traffic. The second is a 3D view that augments the 2D view by preserving the physical network topology and providing a context that is familiar to the application developers. Using the massively parallel multi-physics code pF3D as a case study, we demonstrate that our tool provides valuable insight that we use to explain and optimize pF3D’s performance on an IBM Blue Gene/P system.
J.A. Levine, S. Jadhav, H. Bhatia, V. Pascucci, P.-T. Bremer.
“A Quantized Boundary Representation of 2D Flows,” In Computer Graphics Forum, Vol. 31, No. 3 Pt. 1, pp. 945--954. June, 2012.
DOI: 10.1111/j.1467-8659.2012.03087.x
ABSTRACT

Analysis and visualization of complex vector fields remain major challenges when studying large scale simulation of physical phenomena. The primary reason is the gap between the concepts of smooth vector field theory and their computational realization. In practice, researchers must choose between either numerical techniques, with limited or no guarantees on how they preserve fundamental invariants, or discrete techniques which limit the precision at which the vector field can be represented. We propose a new representation of vector fields that combines the advantages of both approaches. In particular, we represent a subset of possible streamlines by storing their paths as they traverse the edges of a triangulation. Using only a finite set of streamlines creates a fully discrete version of a vector field that nevertheless approximates the smooth flow up to a user controlled error bound. The discrete nature of our representation enables us to directly compute and classify analogues of critical points, closed orbits, and other common topological structures. Further, by varying the number of divisions (quantizations) used per edge, we vary the resolution used to represent the field, allowing for controlled precision. This representation is compact in memory and supports standard vector field operations.